/* ** Common type has only the common header */ structGCObject { CommonHeader; };
可回收的类型,都继承自GCObject
TString
Udata
Proto
Closure
Table
TString的定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* ** Header for string value; string bytes follow the end of this structure ** (aligned according to 'UTString'; see next). */ typedefstructTString { CommonHeader; lu_byte extra; /* reserved words for short strings; "has hash" for longs */ lu_byte shrlen; /* length for short strings */ unsignedint hash; union { size_t lnglen; /* length for long strings */ structTString *hnext;/* linked list for hash table */ } u; } TString;
Udata定义
1 2 3 4 5 6 7 8 9 10 11
/* ** Header for userdata; memory area follows the end of this structure ** (aligned according to 'UUdata'; see next). */ typedefstructUdata { CommonHeader; lu_byte ttuv_; /* user value's tag */ structTable *metatable; size_t len; /* number of bytes */ unionValueuser_;/* user value */ } Udata;
/* ** Function Prototypes */ typedefstructProto { CommonHeader; lu_byte numparams; /* number of fixed parameters */ lu_byte is_vararg; lu_byte maxstacksize; /* number of registers needed by this function */ int sizeupvalues; /* size of 'upvalues' */ int sizek; /* size of 'k' */ int sizecode; int sizelineinfo; int sizep; /* size of 'p' */ int sizelocvars; int linedefined; int lastlinedefined; TValue *k; /* constants used by the function */ Instruction *code; /* opcodes */ structProto **p;/* functions defined inside the function */ int *lineinfo; /* map from opcodes to source lines (debug information) */ LocVar *locvars; /* information about local variables (debug information) */ Upvaldesc *upvalues; /* upvalue information */ structLClosure *cache;/* last-created closure with this prototype */ TString *source; /* used for debug information */ GCObject *gclist; } Proto;
typedefstructCClosure { ClosureHeader; lua_CFunction f; TValue upvalue[1]; /* list of upvalues */ } CClosure;
typedefstructLClosure { ClosureHeader; structProto *p;//lua函数的原型指针 UpVal *upvals[1]; /* list of upvalues */ } LClosure;
Table定义:
1 2 3 4 5 6 7 8 9 10 11 12
typedefstructTable { CommonHeader; lu_byte flags; /* 1<<p means tagmethod(p) is not present */ lu_byte lsizenode; /* log2 of size of 'node' array */ unsignedint sizearray; /* size of 'array' array */ TValue *array; /* array part */ Node *node; Node *lastfree; /* any free position is before this position */ structTable *metatable; GCObject *gclist; } Table;
从面向对象的角度分析的话,可以认为这5种内部基础类型,都继承自GCObject。 创建一个内部对象,使用同一个的接口函数luaC_newobj (lua_State *L, int tt, size_t sz) 参数说明:
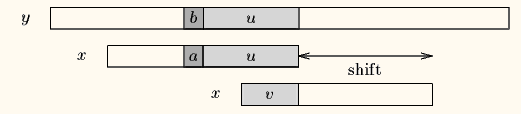
case 2:模式串中有对应的坏字符时,让模式串中最==靠右的对应字符==与坏字符相对 比如还是上图,在第一次右移模式串P的长度后,模式串末尾的c和主串末尾的b不匹配,说明‘b’是坏字符,但是它在模式串P中有两个出现的位置,如果用从末尾开始数的第二个‘b’会太激进,漏掉匹配;所以得用==最右边==的‘b’去匹配,这就是坏字符算法的第二种case。
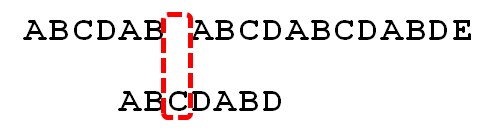
case 1: 模式串中有子串和好后缀==完全匹配==,则将==失配位置前最靠右==的那个子串移动到好后缀的位置继续进行匹配 比如下面的例子,第一步在5的位置text的‘c’和pattern的‘b’失配了,说明‘c’是个坏字符,并且‘c’在pattern中有出现,那按照上面坏字符算法的case 2移动pattern最右边的‘c’与text失配的位置5中去继续匹配。接下来在位置7中,text的‘a’和pattern的‘b’失配了,如果坏字符的规则相当于走回头路了,所以保守一点移动一步,有没有更好的?可以看到按好字后缀的定义,8和9位置的‘ab’是好的后缀,并且它们在pattern模式串中有‘ab’和它完全匹配,那就是这种case,移动到完全匹配的位置,这样一次移动了两步,多走了一步,优秀了一点。
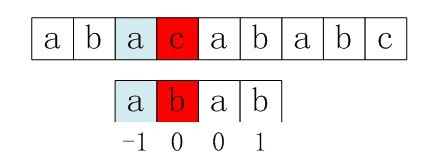
case 2: 模式串种字串和好后缀只能部分匹配,那就从模式串中找到具有如下特征的最长子串,使得P[m-s…m]=P[0…s]。就是从模式串P的第0个元素开始找,找能匹配最长的部分模式串(为啥从0开始而不是找最右边出现的?) 比如下面的例子,一利用花字符算法移动4位,然后在位置4处text的‘a’和pattern的‘b’失配了,如果按坏字符规则要走回头路,所以保守一点右移一步?看看完整的好的后缀为‘cbab’,显然pattern中没有完整能匹配这个完整的‘cbab’后缀的,那就按这种case,取最长的在pattern中出现的部分后缀‘ab’去对应,但是这里有个限制,就是如果是部分后缀匹配,那==只能从pattern的头开始==。想下为啥得这样?这样的话拿pattern的头部的‘ab’去匹配text的部分后缀‘ab’,一下就移动了4位,➡又优秀。
case 3: 如果完全不存在和好后缀匹配的子串,则右移整个模式串,这种情况和坏字符在pattern中没有出现一样,因为怎么都不会匹配成功的
案例分析 接下来拿Moore教授自己的案例来分析整个过程,模式串为EXAMPLE,主串为:HERE IS A SIMPLE EXAMPLE
案例 比如在ABCDE里去匹配BCD,我们用q表示常数primeRK BCD的hash计算出来应该是B q^2 + C q + D ABC的hash应该是 A q^2 + B q + C 当D来的时候如何操作的呢?根据之前的规则: [A q^2 + B q + C] q + D - A pow = A q^3 - A pow + B q^2 + C q + D 而这个pow是可以和go源码里一样提前算出来的,所以在失陪时计算下一个hash能在常数时间快速得到,而两个hash值只是数值对比,一样快的飞起。
Fishhook 考虑到过内存访问权限的问题,在 If hooking in __DATA_CONST, make writable before trying to write 和 Properly restore protections for iOS 13 这两个 PR 中,对于 __DATA_CONST 段中的数据,作者在
//获取主程序路径 // Pickup the pointer to the exec path. sExecPath = _simple_getenv(apple, "executable_path"); if (!sExecPath) sExecPath = apple[0]; if ( sExecPath[0] != '/' ) { // have relative path, use cwd to make absolute .... }
//获取进程名称 // Remember short name of process for later logging sExecShortName = ::strrchr(sExecPath, '/'); if ( sExecShortName != NULL ) ++sExecShortName; else sExecShortName = sExecPath;
... ImageLoader::applyInterposingToDyldCache(gLinkContext); // Bind and notify for the inserted images now interposing has been registered if ( sInsertedDylibCount > 0 ) { for(unsigned int i=0; i < sInsertedDylibCount; ++i) { ImageLoader* image = sAllImages[i+1]; image->recursiveBind(gLinkContext, sEnv.DYLD_BIND_AT_LAUNCH, true); } }
// <rdar://problem/12186933> do weak binding only after all inserted images linked sMainExecutable->weakBind(gLinkContext); gLinkContext.linkingMainExecutable = false;
/*********************************************************************** *_objc_init * Bootstrap initialization. Registers our image notifier with dyld. * Called by libSystem BEFORE library initialization time **********************************************************************/
void _objc_init(void) { static bool initialized = false; if (initialized) return; initialized = true; // fixme defer initialization until an objc-using image is found? environ_init(); tls_init(); static_init(); lock_init(); exception_init(); //注册回调函数 _dyld_objc_notify_register(&map_images, load_images, unmap_image); }
看 _dyld_objc_notify_register 注释
1 2 3 4 5 6
* _objc_init * Bootstrap initialization. Registers our image notifier with dyld. * //引导程序初始化。 用dyld注册我们的image通知程序。 * Called by libSystem BEFORE library initialization time * //在库初始化之前由libSystem调用!!!!! *
/*********************************************************************** * _objc_init * Bootstrap initialization. Registers our image notifier with dyld. * Called by libSystem BEFORE library initialization time **********************************************************************/
void _objc_init(void) { staticbool initialized = false; if (initialized) return; initialized = true; // fixme defer initialization until an objc-using image is found? //读取影响运行时的环境变量。 environ_init(); tls_init(); //运行C ++静态构造函数。libc在dyld调用我们的静态构造函数之前调用_objc_init() static_init(); lock_init(); //初始化libobjc的异常处理系统。由map_images()调用。 exception_init();
/*********************************************************************** * _read_images * Perform initial processing of the headers in the linked * list beginning with headerList. * * Called by: map_images_nolock * * Locking: runtimeLock acquired by map_images **********************************************************************/ void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses) {
定义一系列局部变量 ......
1. 重新初始化TaggedPointer环境**************** if (!doneOnce) { doneOnce = YES;
......
if (DisableTaggedPointers) { disableTaggedPointers(); } initializeTaggedPointerObfuscator();
// Discover classes. Fix up unresolved future classes. Mark bundle classes. 2. 开始遍历头文件,进行类与元类的读取操作并标记(旧类改动后会生成新的类,并重映射到新的类上)************************
for (EACH_HEADER) { //从头文件中拿到类的信息 classref_t *classlist = _getObjc2ClassList(hi, &count); if (! mustReadClasses(hi)) { // Image is sufficiently optimized that we need not call readClass() continue; }
for (i = 0; i < count; i++) { Class cls = (Class)classlist[i]; //!!!!!!核心操作,readClass读取类的信息及类的更新 Class newCls = readClass(cls, headerIsBundle, headerIsPreoptimized); ...... } } ......
3. 读取@selector************************************* // Fix up @selector references staticsize_t UnfixedSelectors; { mutex_locker_tlock(selLock); for (EACH_HEADER) { if (hi->isPreoptimized()) continue; bool isBundle = hi->isBundle(); SEL *sels = _getObjc2SelectorRefs(hi, &count); UnfixedSelectors += count; for (i = 0; i < count; i++) { constchar *name = sel_cname(sels[i]); sels[i] = sel_registerNameNoLock(name, isBundle); } } }


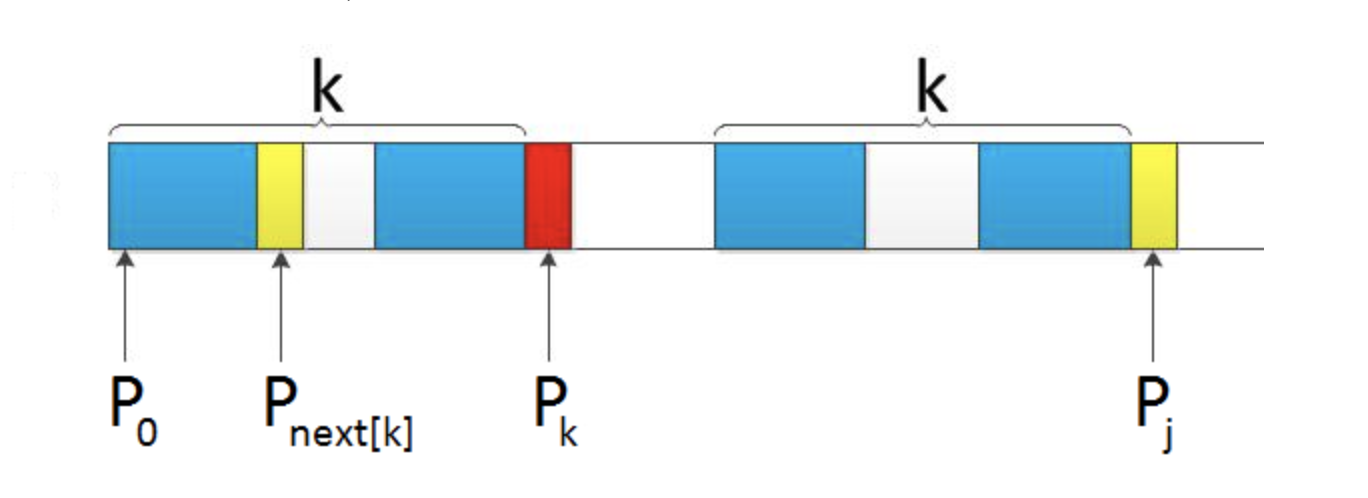
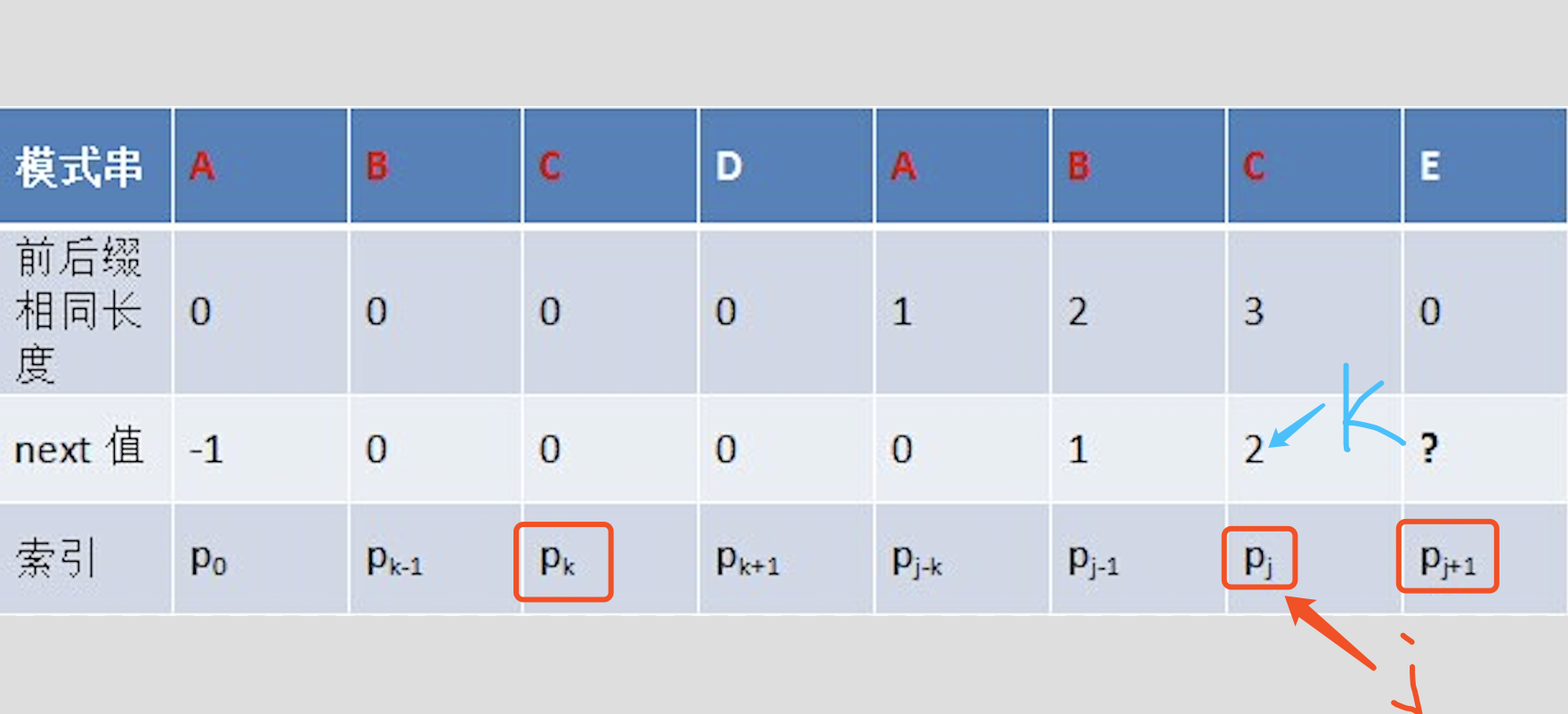 但如果====pk== != pj== 呢?说明“p0 pk-1 pk” ≠ “pj-k pj-1 pj”。换言之,当pk != pj后,字符E前有多大长度的相同前缀后缀呢?很明显,因为C不同于D,所以ABC 跟 ABD不相同,即字符E前的模式串没有长度为k+1的相同前缀后缀,也就不能再简单的令:next[j + 1] = next[j] + 1。所以,这个时候可以去找p[k]的前缀中有没有合适的前缀。见下图递归推导过程
但如果====pk== != pj== 呢?说明“p0 pk-1 pk” ≠ “pj-k pj-1 pj”。换言之,当pk != pj后,字符E前有多大长度的相同前缀后缀呢?很明显,因为C不同于D,所以ABC 跟 ABD不相同,即字符E前的模式串没有长度为k+1的相同前缀后缀,也就不能再简单的令:next[j + 1] = next[j] + 1。所以,这个时候可以去找p[k]的前缀中有没有合适的前缀。见下图递归推导过程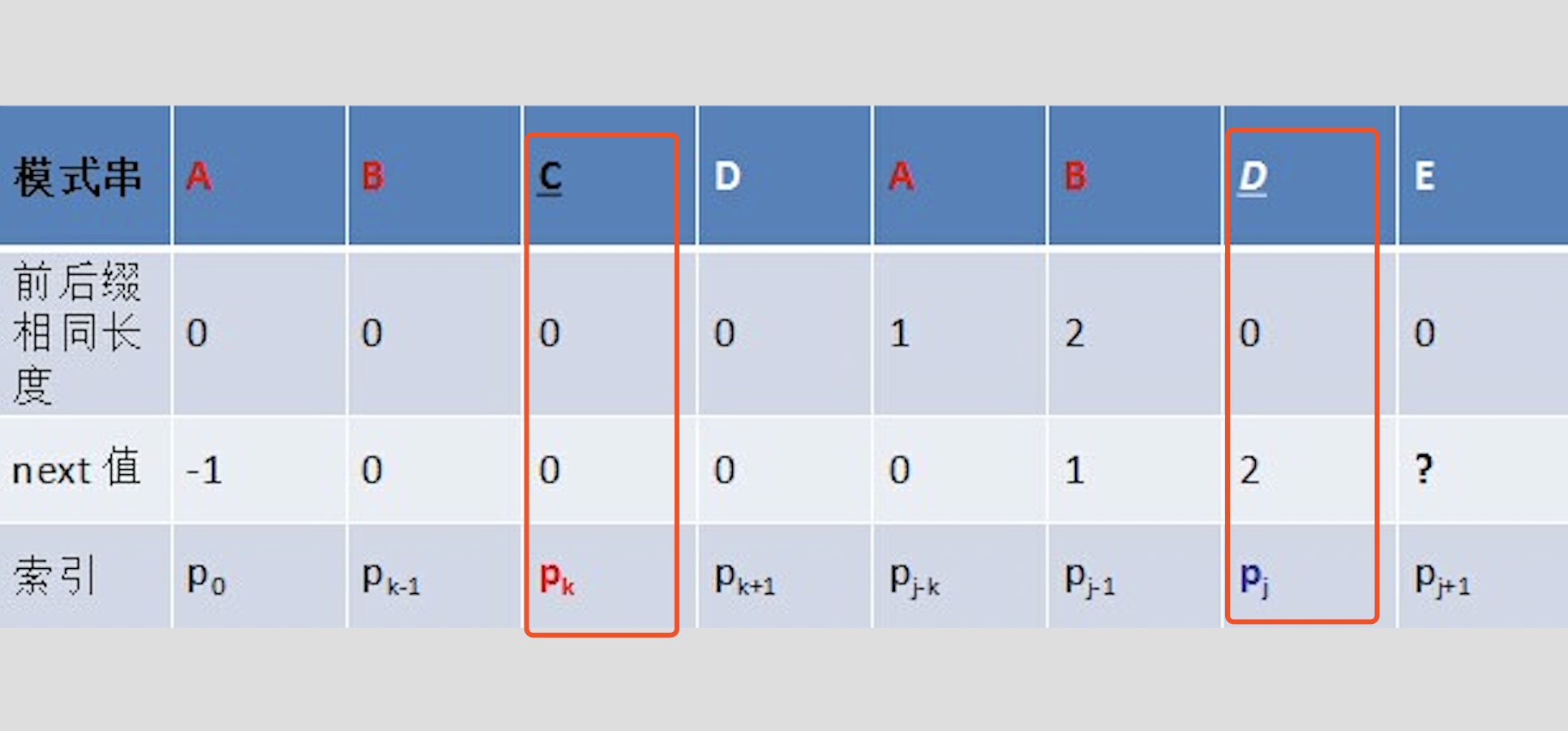




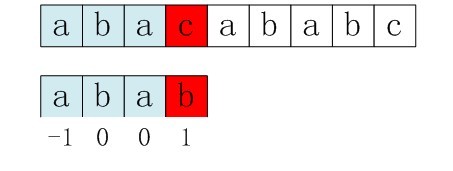
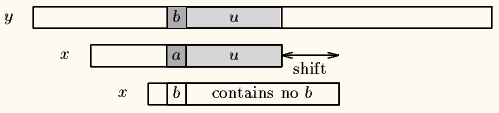 比如还是上图,在第一次右移模式串P的长度后,模式串末尾的c和主串末尾的b不匹配,说明‘b’是坏字符,但是它在模式串P中有两个出现的位置,如果用从末尾开始数的第二个‘b’会太激进,漏掉匹配;所以得用==最右边==的‘b’去匹配,这就是坏字符算法的第二种case。
比如还是上图,在第一次右移模式串P的长度后,模式串末尾的c和主串末尾的b不匹配,说明‘b’是坏字符,但是它在模式串P中有两个出现的位置,如果用从末尾开始数的第二个‘b’会太激进,漏掉匹配;所以得用==最右边==的‘b’去匹配,这就是坏字符算法的第二种case。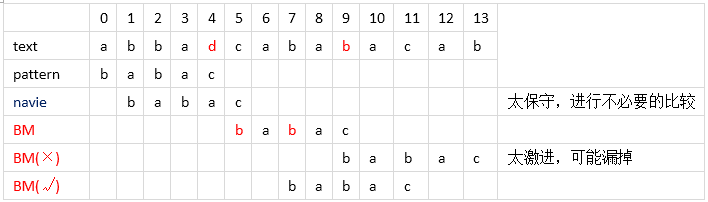
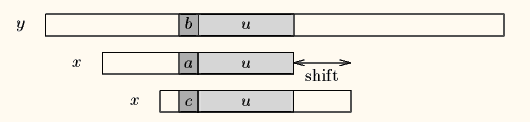 比如下面的例子,第一步在5的位置text的‘c’和pattern的‘b’失配了,说明‘c’是个坏字符,并且‘c’在pattern中有出现,那按照上面坏字符算法的case 2移动pattern最右边的‘c’与text失配的位置5中去继续匹配。接下来在位置7中,text的‘a’和pattern的‘b’失配了,如果坏字符的规则相当于走回头路了,所以保守一点移动一步,有没有更好的?可以看到按好字后缀的定义,8和9位置的‘ab’是好的后缀,并且它们在pattern模式串中有‘ab’和它完全匹配,那就是这种case,移动到完全匹配的位置,这样一次移动了两步,多走了一步,优秀了一点。
比如下面的例子,第一步在5的位置text的‘c’和pattern的‘b’失配了,说明‘c’是个坏字符,并且‘c’在pattern中有出现,那按照上面坏字符算法的case 2移动pattern最右边的‘c’与text失配的位置5中去继续匹配。接下来在位置7中,text的‘a’和pattern的‘b’失配了,如果坏字符的规则相当于走回头路了,所以保守一点移动一步,有没有更好的?可以看到按好字后缀的定义,8和9位置的‘ab’是好的后缀,并且它们在pattern模式串中有‘ab’和它完全匹配,那就是这种case,移动到完全匹配的位置,这样一次移动了两步,多走了一步,优秀了一点。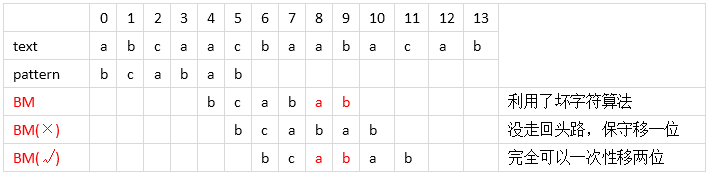
 比如下面的例子,一利用花字符算法移动4位,然后在位置4处text的‘a’和pattern的‘b’失配了,如果按坏字符规则要走回头路,所以保守一点右移一步?看看完整的好的后缀为‘cbab’,显然pattern中没有完整能匹配这个完整的‘cbab’后缀的,那就按这种case,取最长的在pattern中出现的部分后缀‘ab’去对应,但是这里有个限制,就是如果是部分后缀匹配,那==只能从pattern的头开始==。想下为啥得这样?这样的话拿pattern的头部的‘ab’去匹配text的部分后缀‘ab’,一下就移动了4位,➡又优秀。
比如下面的例子,一利用花字符算法移动4位,然后在位置4处text的‘a’和pattern的‘b’失配了,如果按坏字符规则要走回头路,所以保守一点右移一步?看看完整的好的后缀为‘cbab’,显然pattern中没有完整能匹配这个完整的‘cbab’后缀的,那就按这种case,取最长的在pattern中出现的部分后缀‘ab’去对应,但是这里有个限制,就是如果是部分后缀匹配,那==只能从pattern的头开始==。想下为啥得这样?这样的话拿pattern的头部的‘ab’去匹配text的部分后缀‘ab’,一下就移动了4位,➡又优秀。

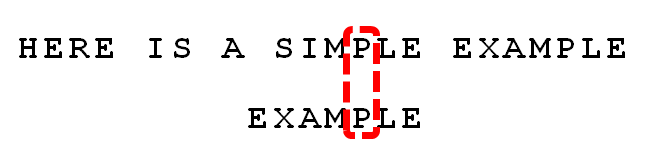

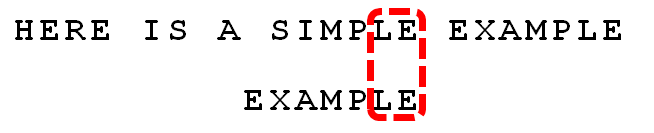
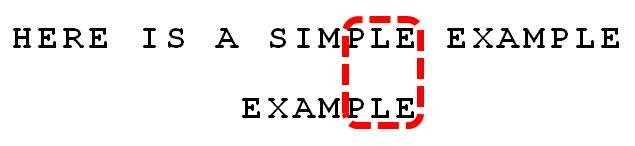

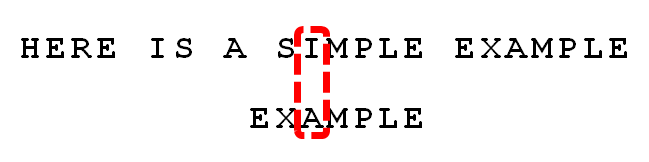
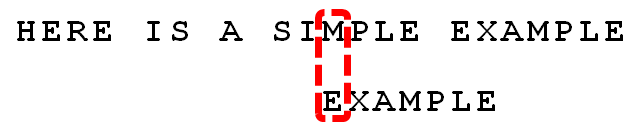
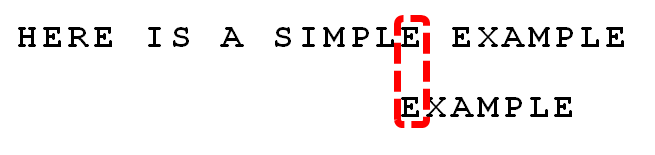
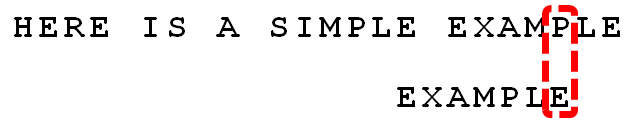

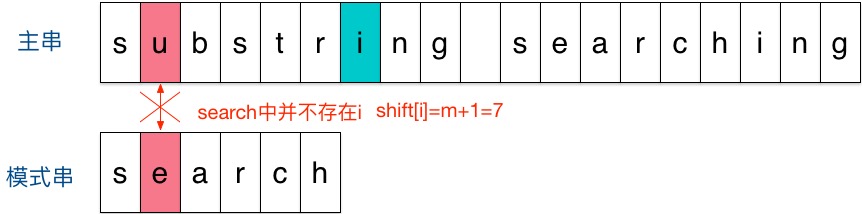
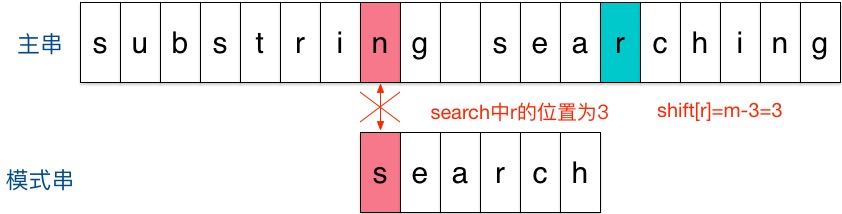
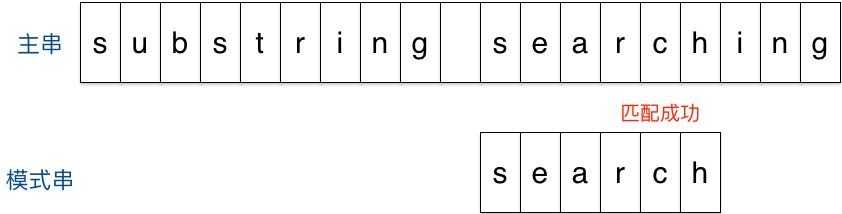
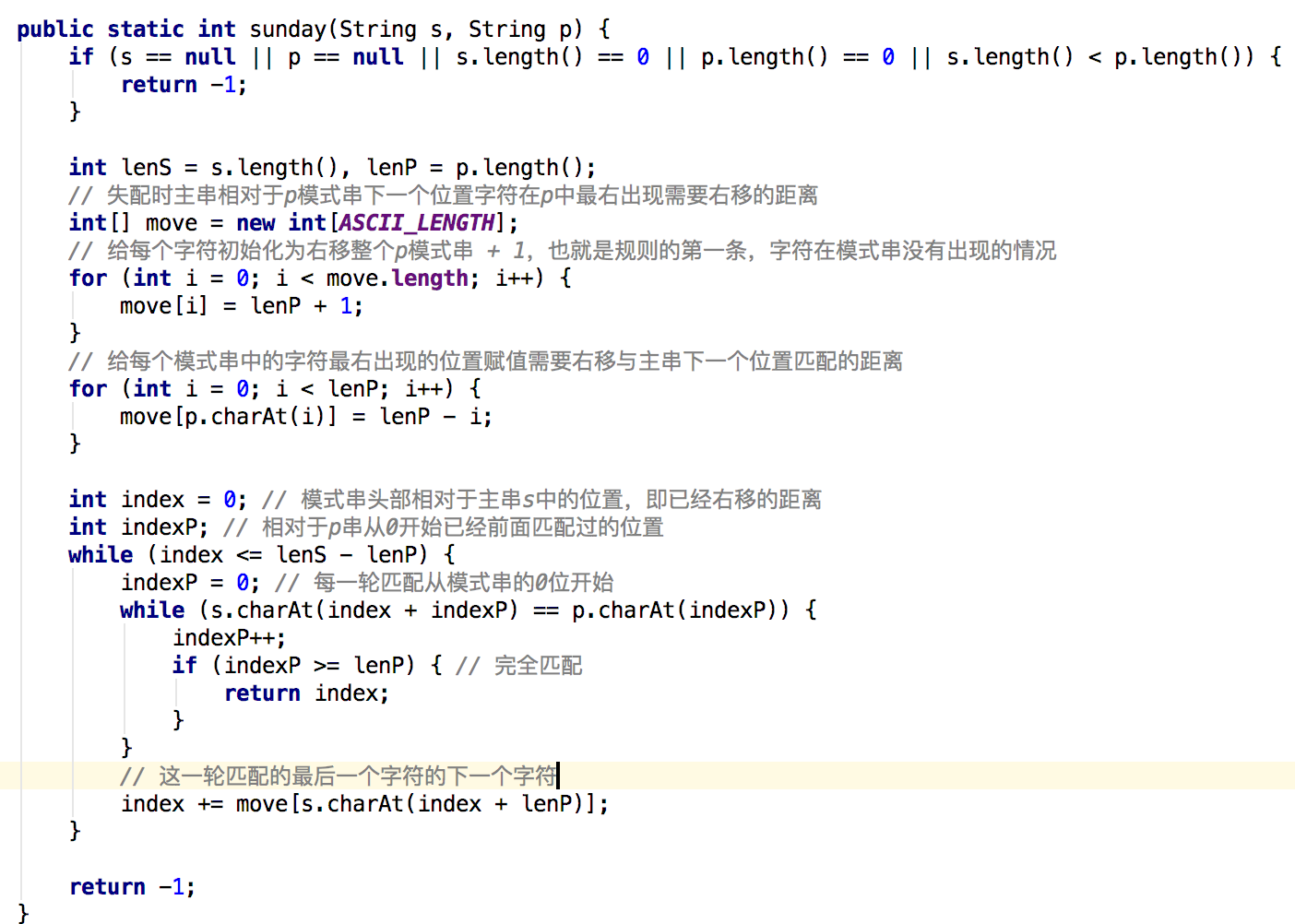
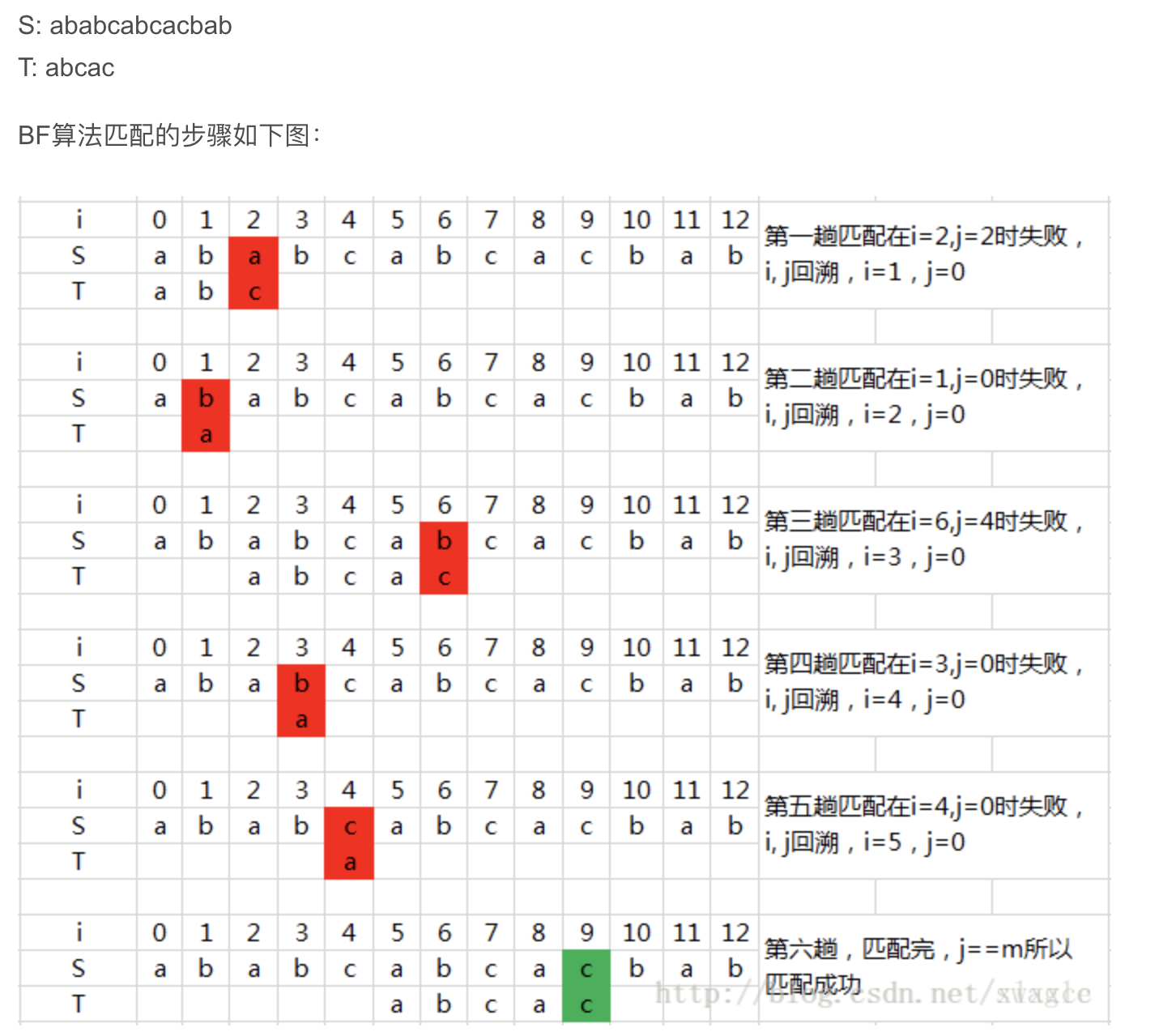
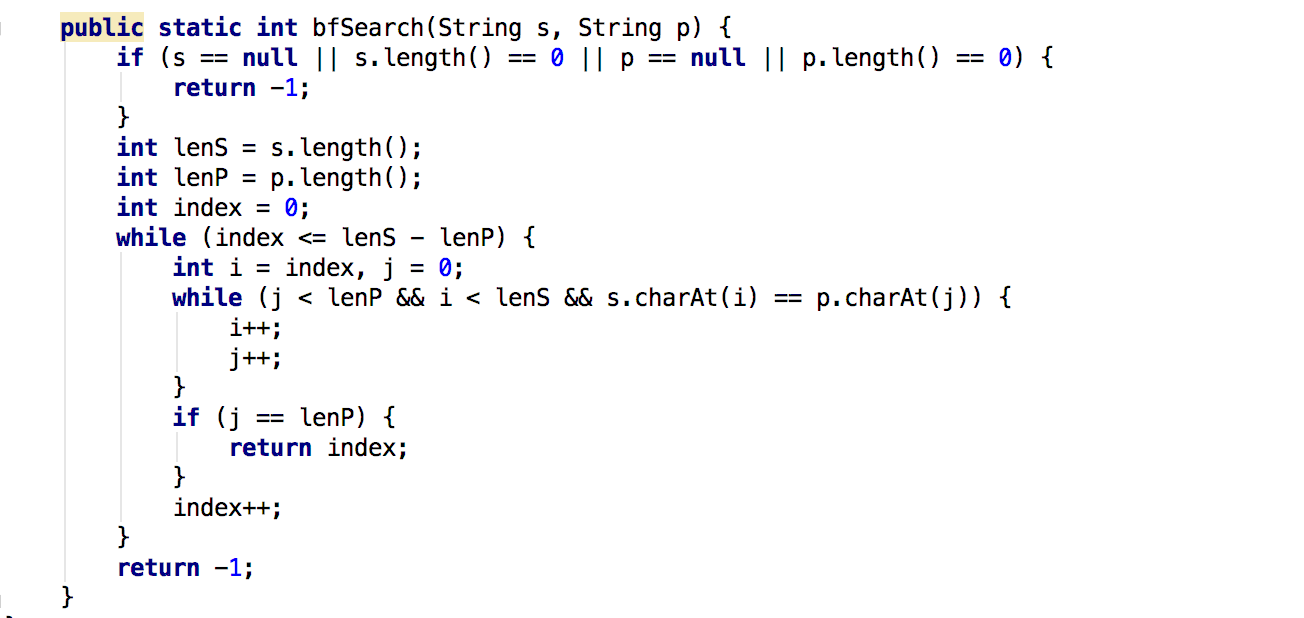
 匹配算法
匹配算法
