基本分类:
1.朴素法:BF(Brute Force)
暴风(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。
思路
首先S[1]和T[1]比较,若相等,则再比较S[2]和T[2],一直到T[M]为止;若S[1]和T[1]不等,则S向右移动一个字符的位置,再依次进行比较。如果存在k,1≤k≤N,且S[k+1…k+M]=T[1…M],则匹配成功;否则失败。该算法最坏情况下要进行M*(N-M+1)次比较,时间复杂度为O(M*N)
匹配过程
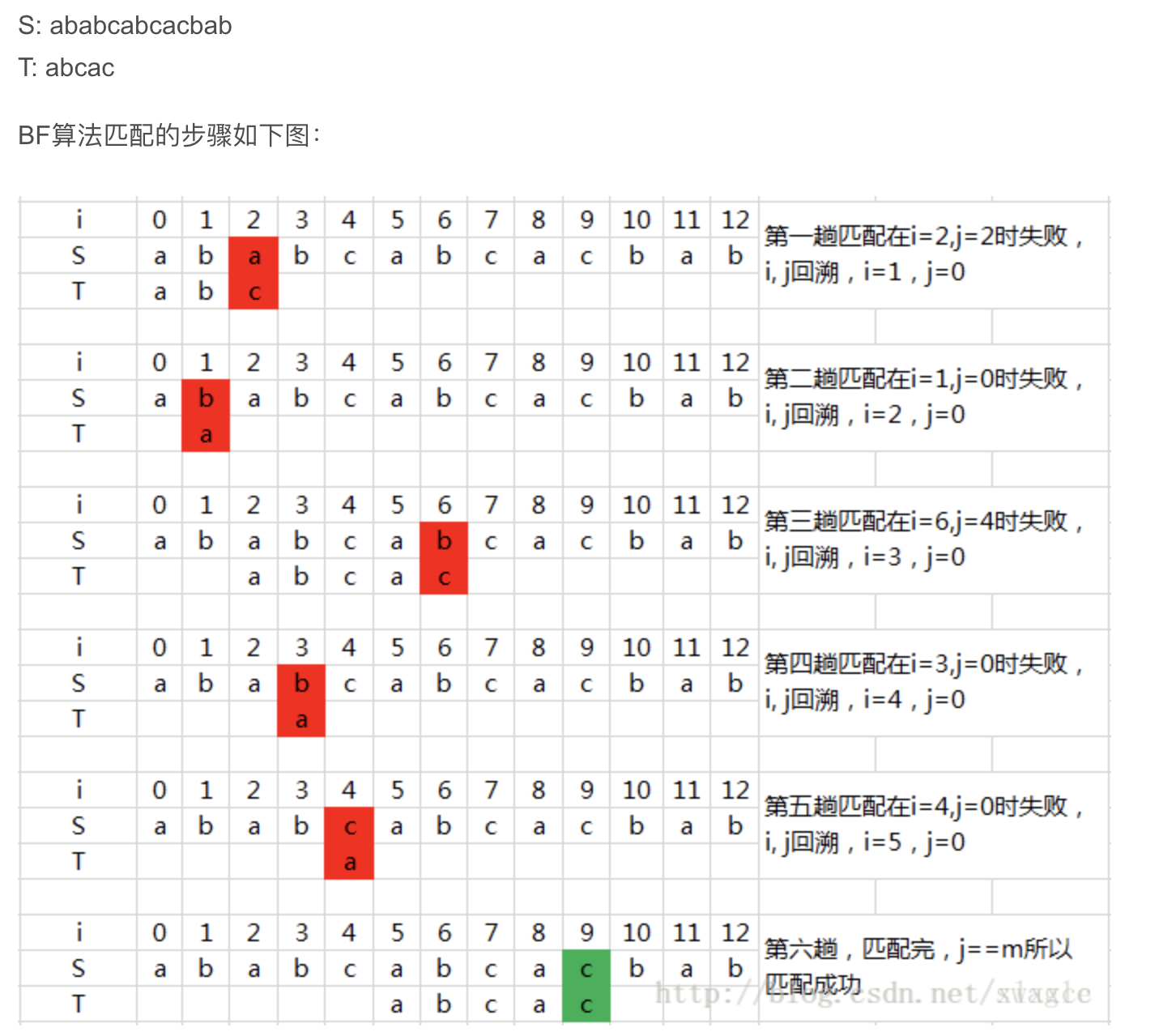
代码
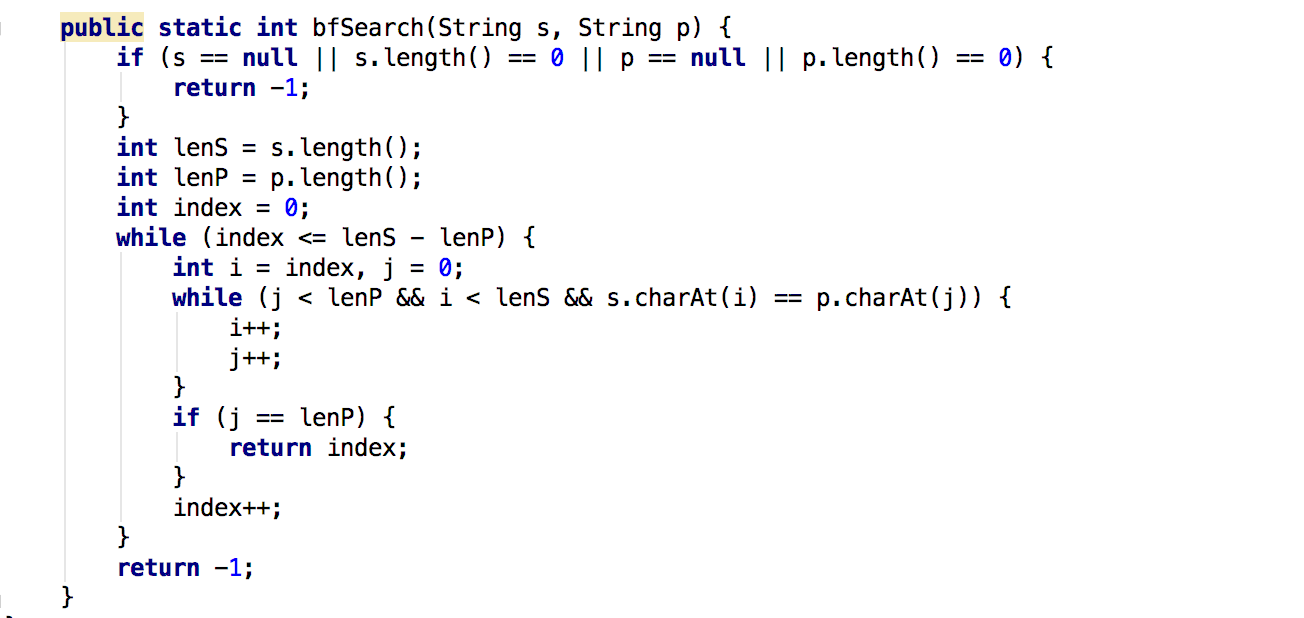
2.基于前后缀
KMP
思路
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置。如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值),即移动的实际位数为:j - next[j],且此值大于等于1。next 数组各值的含义:代表当前字符==之前:不包括自身==的字符串中,有多大长度的相同前缀后缀。例如如果next [j] =k,代表j之前的字符串中有最大长度为k的相同前缀后缀。此也意味着在某个字符失配时,该字符对应的next值会告诉你下一步匹配中,模式串应该跳到哪个位置(跳到next [j] 的位置)。如果next [j] 等于0或-1,则跳到模式串的开头字符,若next [j] = k 且 k > 0,代表下次匹配跳到j 之前的某个字符,==而不是跳到开头,且具体跳过了k 个字符,这就是KMP相对于BF的优化==。
最长前缀后缀表
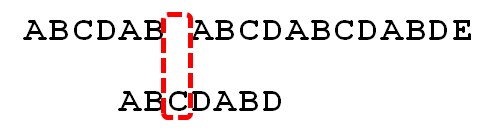
对于P = p0 p1 …pj-1 pj,寻找模式串P中长度最大且相等的前缀和后缀。如果存在p0 p1 …pk-1 pk = pj- k pj-k+1…pj-1 pj,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。比如求模式串“ABCDABD”的最长前缀后缀表过程:
所以最后求得的模式串“ABCDABD”的最长前缀后缀表为:
根据前缀后缀表推导next数组
next 数组考虑的是==除当前字符外==的最长相同前缀后缀,所以通过前面最长前缀后缀表求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将前面最长前缀后缀表中求得的值整体右移一位,然后初值赋为-1,如下表格所示:
如何求next数组
- 根据前面匹配的求后一个的next
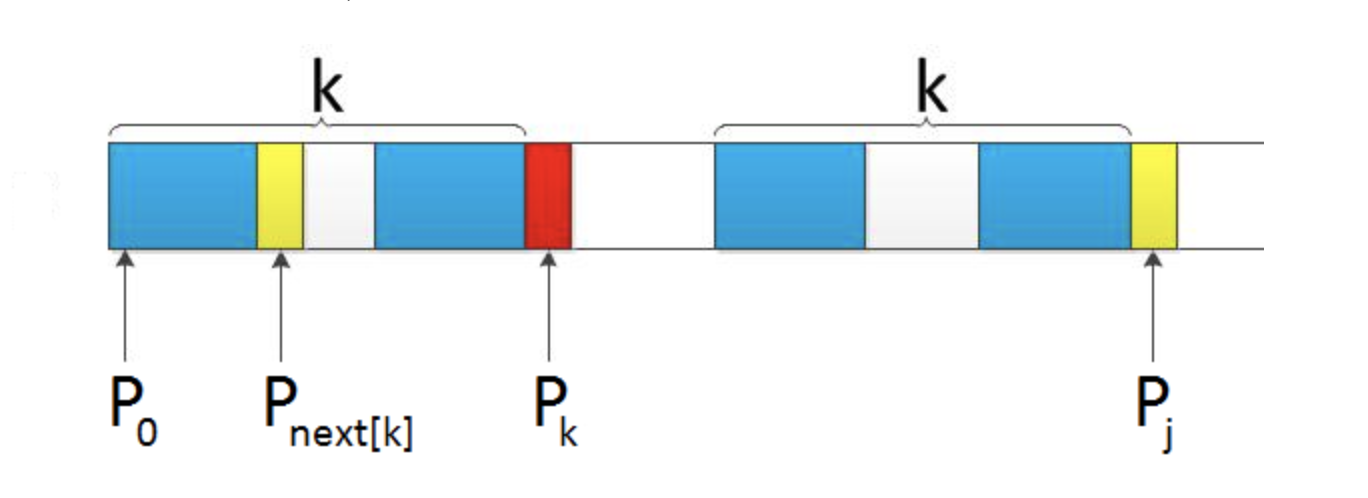
给定模式串ABCDABCE,且已知next [j] = k(相当于“p0 pk-1” = “pj-k pj-1” = AB,可以看出k为2),现要求next [j + 1]等于多少?因为pk = pj = C,所以next[j + 1] = next[j] + 1 = k + 1(可以看出next[j + 1] = 3)。代表字符E前的模式串中,有长度k+1 的相同前缀后缀。
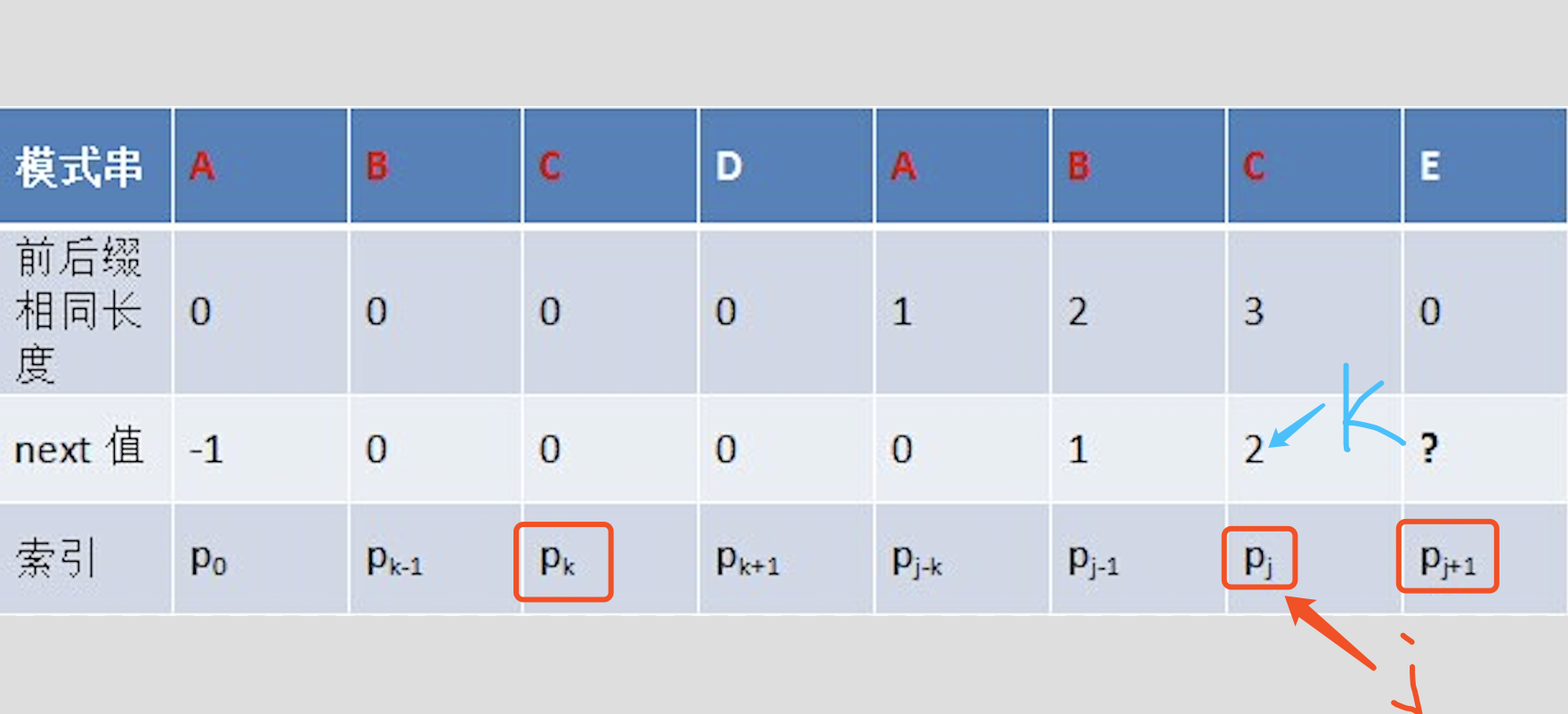 但如果====pk== != pj== 呢?说明“p0 pk-1 pk” ≠ “pj-k pj-1 pj”。换言之,当pk != pj后,字符E前有多大长度的相同前缀后缀呢?很明显,因为C不同于D,所以ABC 跟 ABD不相同,即字符E前的模式串没有长度为k+1的相同前缀后缀,也就不能再简单的令:next[j + 1] = next[j] + 1。所以,这个时候可以去找p[k]的前缀中有没有合适的前缀。见下图递归推导过程
但如果====pk== != pj== 呢?说明“p0 pk-1 pk” ≠ “pj-k pj-1 pj”。换言之,当pk != pj后,字符E前有多大长度的相同前缀后缀呢?很明显,因为C不同于D,所以ABC 跟 ABD不相同,即字符E前的模式串没有长度为k+1的相同前缀后缀,也就不能再简单的令:next[j + 1] = next[j] + 1。所以,这个时候可以去找p[k]的前缀中有没有合适的前缀。见下图递归推导过程
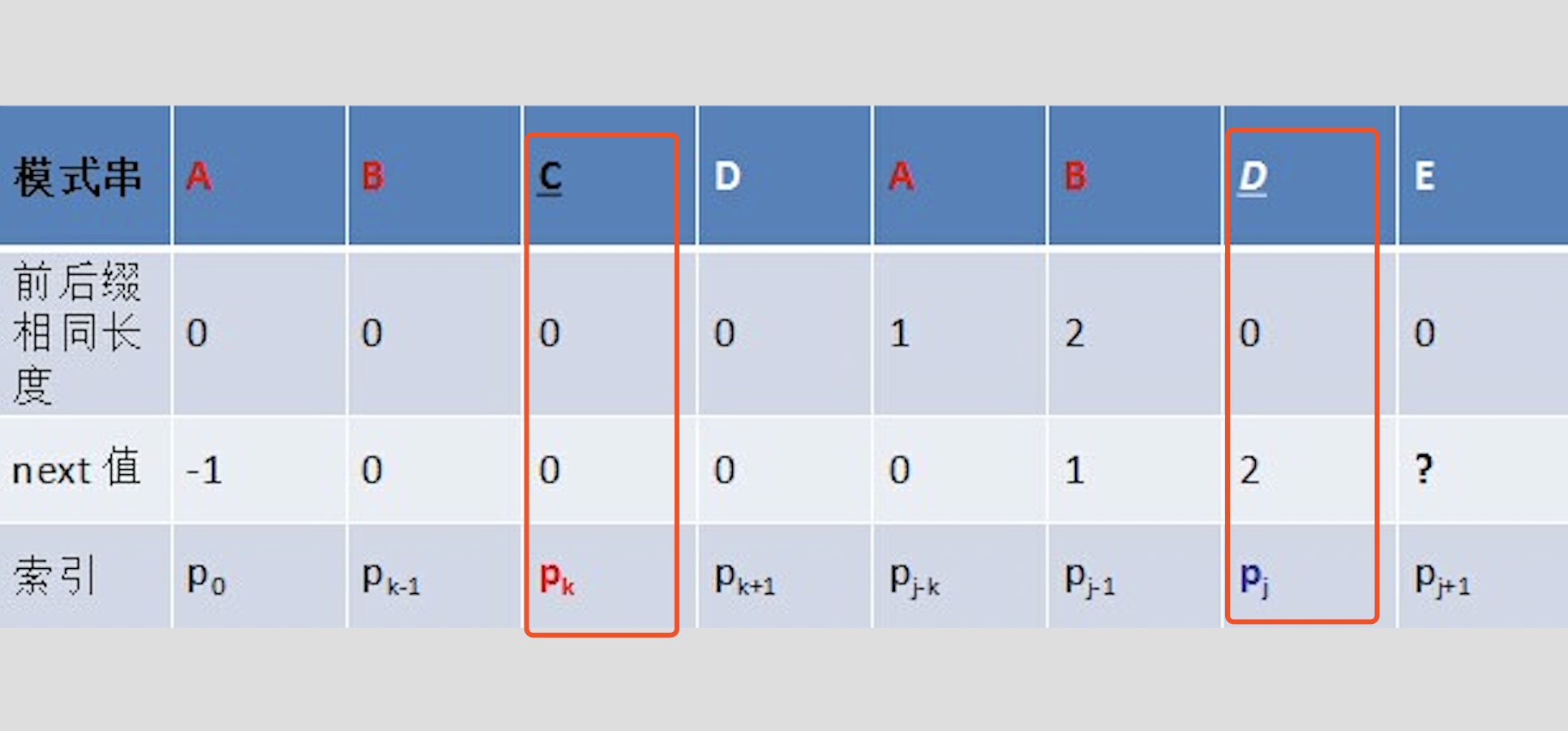
- 递归的推导过程
k = next[k];
待求的是p[j+1],发现p[j] != p[k],那就递归寻找p[next[k]]和p[j]是否一样,如果一样,那next[j+1] = next[next[k] + 1
- 根据前面匹配的求后一个的next
求next数组代码
见IDEA代码匹配过程
假设S=“ABCDAB ABCDABCDABDE”,P=“ABCDABD”- P[0]跟S[4]匹配成功,P[1]跟S[5]也匹配成功…,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j-next[j]=6-2=4位。

- 向右移动4位后,P[2]处的C再次失配,由于C对应的next值为0,所以下一步用P[0]处的字符继续跟S[10]匹配,相当于向右移动:j - next[j] = 2 - 0 = 2 位。
- 移动两位之后,A 跟空格不匹配,模式串后移1 位。

- P[6]处的D再次失配,因为P[6]对应的next值为2,故下一步用P[2]继续跟文本串匹配,当于模式串向右移动 j - next[j] = 6 - 2 = 4 位。

- 匹配成功,过程结束。

- P[0]跟S[4]匹配成功,P[1]跟S[5]也匹配成功…,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j-next[j]=6-2=4位。
kmp算法查找过程
见IDEA代码next数组的优化
比如,求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1,当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。
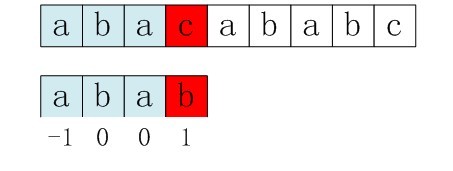
右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?
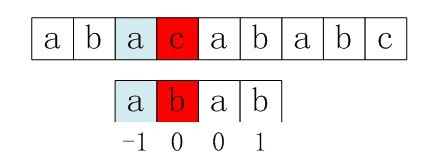
问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]
见IDEA代码时间复杂度
如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。参考资料
- July大神–从头到尾彻底理解KMP
- 7分钟动画理解KMP
BM(Boyer-Moore)
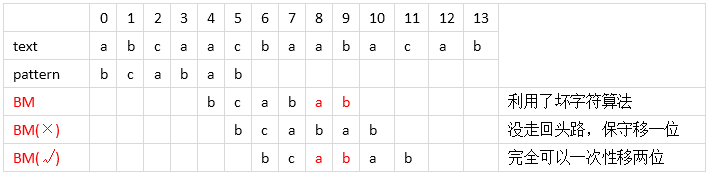
Boyer-Moore算法平均要比KMP快3-5倍,grep,window电脑的查找还有各种文本查找都用的BM算法。它和之前的BF和KMP匹配的过程不大一样,采用的是从后往前对比的过程。BM算法实际上包含两个并行的算法(也就是两个启发策略):坏字符算法(bad-character shift)和好后缀算法(good-suffix shift)。这两种算法的目的就是让模式串每次向右移动尽可能大的距离- 思路
从后往前匹配。如果遇到不一致的字符,则这个字符就是==坏的字符==,所以坏字符是针对匹配串S的;匹配的路上相同的字符以及子集称为==好的后缀==,所以好的字符是针对模式串P的。每次失配时,都要根据这两个启发算法中找到能右移动的最大值。接下来详细讨论坏字符算法和好后缀算法这两个启发式。 - 启发式
- 坏字符算法
当出现一个坏字符时,BM算法向右移动模式串,让模式串中==最靠右的对应字符==与坏字符相对,然后继续匹配。坏字符算法有两种情况。- case 1: 模式串中不存在坏字符。这种情况直接右移模式串P的长度
比如底下的第一次匹配的字符‘d’,在模式串中不存在,直接右移模式串长度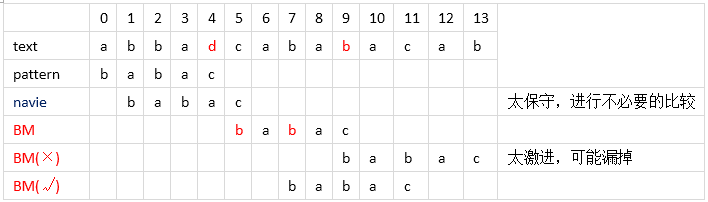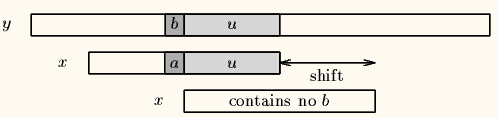 - case 2:模式串中有对应的坏字符时,让模式串中最==靠右的对应字符==与坏字符相对
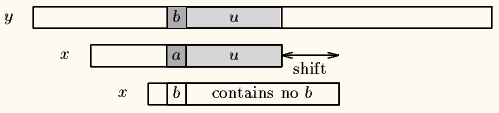 比如还是上图,在第一次右移模式串P的长度后,模式串末尾的c和主串末尾的b不匹配,说明‘b’是坏字符,但是它在模式串P中有两个出现的位置,如果用从末尾开始数的第二个‘b’会太激进,漏掉匹配;所以得用==最右边==的‘b’去匹配,这就是坏字符算法的第二种case。
比如还是上图,在第一次右移模式串P的长度后,模式串末尾的c和主串末尾的b不匹配,说明‘b’是坏字符,但是它在模式串P中有两个出现的位置,如果用从末尾开始数的第二个‘b’会太激进,漏掉匹配;所以得用==最右边==的‘b’去匹配,这就是坏字符算法的第二种case。

- case 1: 模式串中不存在坏字符。这种情况直接右移模式串P的长度
- 好后缀算法
如果匹配了一个好后缀, 并且在模式中还有另外一个相同的完整后缀或后缀的部分, 那把下一个完整后缀或部分移动到当前后缀位置。假如说,P的后u个字符和S都已经匹配了,但是接下来的一个字符不匹配(坏字符),我需要移动才能匹配。如果说后u个字符在P其他位置也出现过或部分出现,我们将P右移到前面的u个字符或部分和最后的u个字符或部分相同,如果说后u个字符在P其他位置完全没有出现,直接右移整个pattern。这样,好后缀算法有三种情况:- case 1:
模式串中有子串和好后缀==完全匹配==,则将==失配位置前最靠右==的那个子串移动到好后缀的位置继续进行匹配
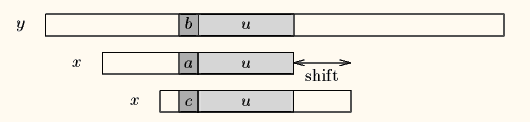 比如下面的例子,第一步在5的位置text的‘c’和pattern的‘b’失配了,说明‘c’是个坏字符,并且‘c’在pattern中有出现,那按照上面坏字符算法的case 2移动pattern最右边的‘c’与text失配的位置5中去继续匹配。接下来在位置7中,text的‘a’和pattern的‘b’失配了,如果坏字符的规则相当于走回头路了,所以保守一点移动一步,有没有更好的?可以看到按好字后缀的定义,8和9位置的‘ab’是好的后缀,并且它们在pattern模式串中有‘ab’和它完全匹配,那就是这种case,移动到完全匹配的位置,这样一次移动了两步,多走了一步,优秀了一点。
比如下面的例子,第一步在5的位置text的‘c’和pattern的‘b’失配了,说明‘c’是个坏字符,并且‘c’在pattern中有出现,那按照上面坏字符算法的case 2移动pattern最右边的‘c’与text失配的位置5中去继续匹配。接下来在位置7中,text的‘a’和pattern的‘b’失配了,如果坏字符的规则相当于走回头路了,所以保守一点移动一步,有没有更好的?可以看到按好字后缀的定义,8和9位置的‘ab’是好的后缀,并且它们在pattern模式串中有‘ab’和它完全匹配,那就是这种case,移动到完全匹配的位置,这样一次移动了两步,多走了一步,优秀了一点。
- case 2:
模式串种字串和好后缀只能部分匹配,那就从模式串中找到具有如下特征的最长子串,使得P[m-s…m]=P[0…s]。就是从模式串P的第0个元素开始找,找能匹配最长的部分模式串(为啥从0开始而不是找最右边出现的?)
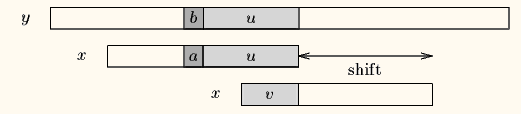 比如下面的例子,一利用花字符算法移动4位,然后在位置4处text的‘a’和pattern的‘b’失配了,如果按坏字符规则要走回头路,所以保守一点右移一步?看看完整的好的后缀为‘cbab’,显然pattern中没有完整能匹配这个完整的‘cbab’后缀的,那就按这种case,取最长的在pattern中出现的部分后缀‘ab’去对应,但是这里有个限制,就是如果是部分后缀匹配,那==只能从pattern的头开始==。想下为啥得这样?这样的话拿pattern的头部的‘ab’去匹配text的部分后缀‘ab’,一下就移动了4位,➡又优秀。
比如下面的例子,一利用花字符算法移动4位,然后在位置4处text的‘a’和pattern的‘b’失配了,如果按坏字符规则要走回头路,所以保守一点右移一步?看看完整的好的后缀为‘cbab’,显然pattern中没有完整能匹配这个完整的‘cbab’后缀的,那就按这种case,取最长的在pattern中出现的部分后缀‘ab’去对应,但是这里有个限制,就是如果是部分后缀匹配,那==只能从pattern的头开始==。想下为啥得这样?这样的话拿pattern的头部的‘ab’去匹配text的部分后缀‘ab’,一下就移动了4位,➡又优秀。 - case 3:
如果完全不存在和好后缀匹配的子串,则右移整个模式串,这种情况和坏字符在pattern中没有出现一样,因为怎么都不会匹配成功的
- case 1:
- 坏字符算法
- 案例分析
接下来拿Moore教授自己的案例来分析整个过程,模式串为EXAMPLE,主串为:HERE IS A SIMPLE EXAMPLE- 上来text的‘S’和pattern的‘E’不匹配,所以‘S’是坏字符,并且‘S’在pattern中不存在,所以按照坏字符算法case 1,直接向右移动pattern的长度7位。

- 接下来text的‘P’和pattern的‘E’不匹配,所以‘P’也是坏字符,但是‘P’在pattern中存在,所以按照坏字符算法case 2,让pattern中最靠右的‘P’与之对齐,也就是向右移动2位

- 按上面移动后
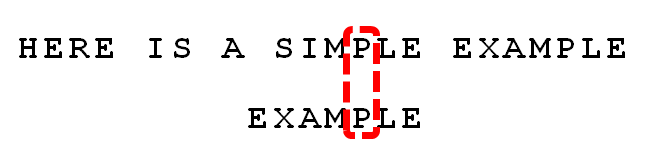
- 然后从末尾开始依次往前面匹配

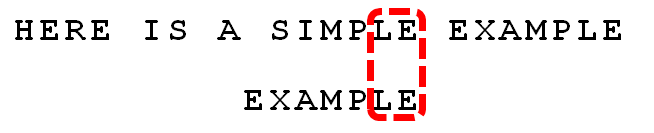
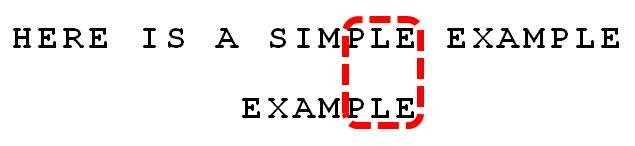

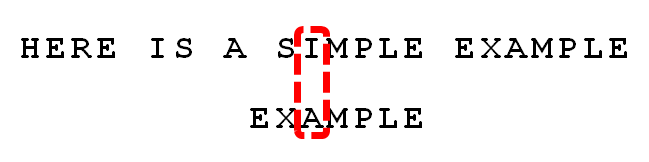
- 注意上面的红框,在text的‘I’和pattern的‘A’失配的时候,‘I’是坏字符,而‘E’,‘LE’,‘PLE’,‘MPLE’都是好的后缀。如果按坏字符的话,因为‘I’在pattern中没有出现,那么需要整个都移动到‘I’的后面,也就是下面这样移动,只能移动==3==位:
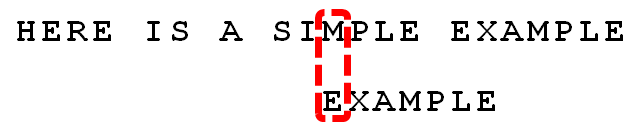
但是因为有这么多的好后缀(MPLE、PLE、LE、E),根据上面好后缀算法,因为MPLE在失配位置前没有完全匹配的,所以case1不满足;接下从(PLE、LE、E)这些匹配的部分后缀中找能在失配位置前==最长的==,并且从pattern的0号位置头部开始的,那只有‘E’满足,所以把pattern头部的‘E’移到和text的‘E’一样的位置重新开始匹配。这样一次就移动了==6==位!显然这样更优秀。
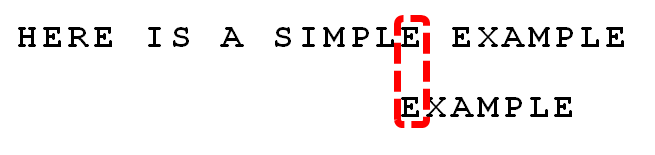
- 接下来继续从尾到头开始匹配,上来就失配了,满足坏字符的case2,所以找到pattern的最靠右边的字符‘P’去匹配
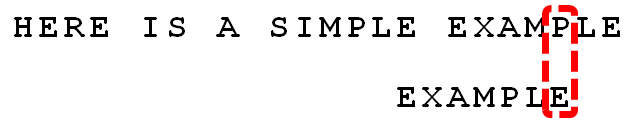
- 从尾到头去匹配,匹配成功

- 上来text的‘S’和pattern的‘E’不匹配,所以‘S’是坏字符,并且‘S’在pattern中不存在,所以按照坏字符算法case 1,直接向右移动pattern的长度7位。
- 参考资料
Moore教授自己的案例demo
阿里小姐姐的分析过程
阮一峰的,得结合上面一起看
- 思路
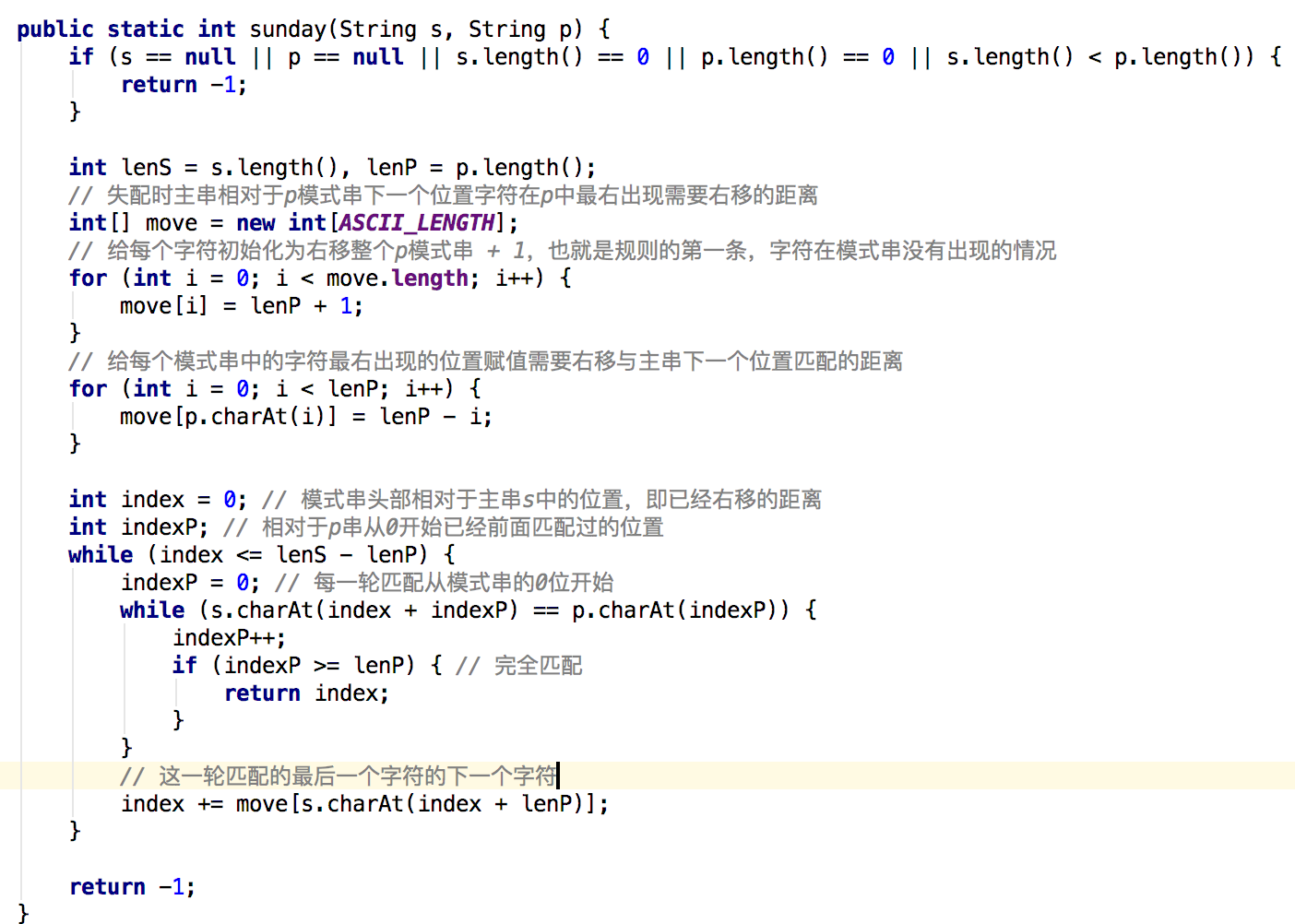
Sunday
- 思路
Sunday算法最主要的特点是匹配失败的时候,关注的是主串中这一轮参与匹配的==最末位字符的下一位字符==,并且和BM不一样的是它是从前往后开始匹配。具体规则是:- 如果该字符(主串失配位置的下一个字符)没有在模式串中出现则直接跳过它,即模式串右移位数 = 模式串长度 + 1。因为下一个不可能在模式串中存在,所以可以大胆的全部跳过它
- 如果在模式串中存在,则模式串右移位数 = 模式串长度 - 该字符最右出现的位置(0开始算) = 模式串中该字符最右出现的位置到尾部的距离 + 1。和BM的坏字符的case 2类型,稳妥起见,拿最右边的相同的字符去对应匹配。
- 案例分析
假设现在要在主串”substring searching”中查找模式串”search”。- 刚开始时,把模式串和主串的左边对齐
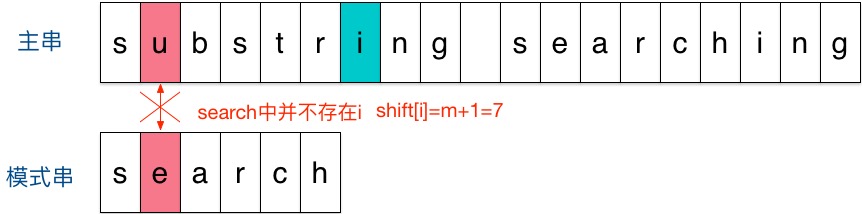
- 发现在第二个字符‘u’和‘e’的时候不匹配,根据规则,不匹配的时候关注主串这一轮参加匹配的的最末尾字符的下一个字符,即蓝色的‘i’,因为‘i’不在模式串中,所以向右移动位数 = 模式串长度 + 1 = 6 + 1 = 7,移动后如下图:
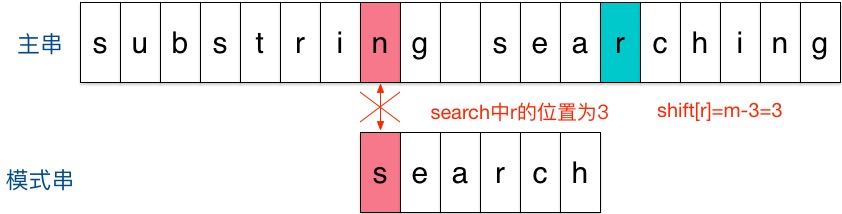
- 继续匹配发现第一个字符就不匹配,按规则还是关注这一轮主串参加匹配的最末尾的字符的下一个字符,即蓝色的‘r’,发现它出现在模式串的倒数第3位,所以向右移动位数 = ‘r’到模式串末尾的距离 + 1 = 2 + 1 = 3,移动后如下图:
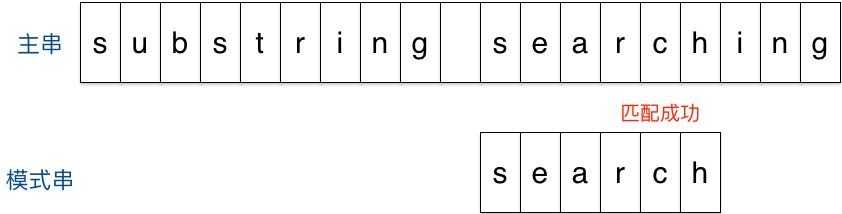
- 匹配成功
- 刚开始时,把模式串和主串的左边对齐
- 代码
- 缺点
Sunday算法的核心在向右移动位数move数组,这个依赖与模式串,所以有可能构造处很差的move数组(move数组的值都为1),比如:
主串:baaaabaaaabaaaabaaaa
模式串:aaaaa
这个模式串中,move[‘a’]的值都为1,因为最右边出现的‘a’就在末尾,所以每次失配时,只能让模式串移动1位,这就退化位BF的朴素算法了,时间复杂度也会飙升到o(m*n),所以sunday不适合这种重复的模式串。 - 参考
参考资料
- 思路
3.基于hash
- Rabin-Karp算法
- 背景
BF这种朴素的字符串匹配算法慢主要有两点:1.每一轮的比较都是一个字符一个字符去比较;2.前一次匹配的信息对于下一次匹配完全用不上。
所以Rabin-Karp算法对这两点进行了改进:一是每一轮的匹配不用一个个字符去比较,而是把模式串和这一轮匹配的主串用对应的hash数值去比较,所以一次就能匹配完;二是当失配时,把第一字符去掉,然后把下一个字符加进去,重新计算hash,但是这次计算hash可以根据上次的hash在常数时间内快速的算出来,这样上一次匹配的信息也能充分利用起来 - 思路
比如我们要在源串”9876543210520”中查找”520”,因为这些字符串中只有数字,所以我们 可以使用字符集{‘0’,’1’,’2’,’3’,’4’,’5’,’6’,’7’,’8’,’9’}来表示字符串中的所有元 素,并且将各个字符映射到数字0~9,然后用M表示字符集中字符的总个数,这里是10, 那么我们就可以将搜索词 “987” 转化为下面的数值:
(“9”的映射值 * M + “8”的映射值) * M + “7”的映射值 = (9 * 10 + 8) * 10 + 7 = 987 分析一下这个数值:987,它可以代表字符串 “987”,其中:
代表字符 “9” 的部分是“ “9”的映射值 * (M 的 n - 1 次方) = 9 * (10 的 2 次方) = 900”
代表字符 “8” 的部分是“ “8”的映射值 * (M 的 n - 2 次方) = 8 * (10 的 1 次方) = 80”
代表字符 “7” 的部分是“ “7”的映射值 * (M 的 n - 3 次方) = 0 * (10 的 0 次方) = 7 其实这就是987按10进制的表达方式,同理可以去算模式串“520”的hash,显然这两个hash值不相等。接下来应该把‘9’去掉,把‘6’加进来。那如何利用前面‘987’计算的hash的信息呢?首先我们把 987 减去代表字符 “9” 的部分:987 - (“9”的映射值 * (M 的 n - 1 次方)) = 987 - (9 * (10 的 2 次方)) = 987 - 900 = 87,然后再乘以 M(这里是 10),再加上 “6” 的映射值,就成了‘876’ :87 * M + “6”的映射值 = 87 * 10 + 6 = 876。然后根据这个规则继续匹配。当两个数值相等时,未必是真正的相等,我们需要进行一次细致的检查(再进行一次朴素的字符串比较)。若不匹配,则可以排除掉,防止hash碰撞的情况。 这里我们列举的是10进制的情况,如果是ASCII 字符集的话M可以取值128;这个M值尽量取较大的素数,这样使得更多的位参与运算减少hash碰撞。如果我们要在 Unicode 字符集范围内查找“搜索词”,由于 Unicode 字符集中有 1114112 个字符,那么 M 就等于 1114112,而 Go 语言中使用 ==16777619== Go的strings源码作为 M 的值,16777619 比 1114112 大(更大的 M 值可以容纳更多的字符,这是可以的),而且 16777619 是一个素数。这样就可以使用上面的方法计算 Unicode 字符串的数值了。进而可以对 Unicode 字符串进行比较了。 - 代码
计算待匹配模式串sep的hash和最高位权重的值pow
 匹配算法
匹配算法

- 案例
比如在ABCDE里去匹配BCD,我们用q表示常数primeRK
BCD的hash计算出来应该是B q^2 + C q + D
ABC的hash应该是 A q^2 + B q + C
当D来的时候如何操作的呢?根据之前的规则:
[A q^2 + B q + C] q + D - A pow = A q^3 - A pow + B q^2 + C q + D
而这个pow是可以和go源码里一样提前算出来的,所以在失陪时计算下一个hash能在常数时间快速得到,而两个hash值只是数值对比,一样快的飞起。 - 参考
Go的strings源码
参考资料1
参考资料2
- 背景
- Rabin-Karp算法
其他
- AC算法
基于前缀的AC算法,构造goto表
参考资料 - Bitmap算法
用一个 bit 位来标记某个元素节省存储空间
参考资料
- AC算法

